Something shifted in enterprise AI conversations this week.
Google called it Agent Identity and Knowledge Catalog. Palantir calls it the Ontology. Gartner calls it Context Graphs. Atlan calls it Context Engineering. The terminology is different. The anxiety underneath it is identical.
The industry has finally named the problem it has been circling for two years.
AI agents can act. They cannot reliably reason about how an organization actually works.
That gap between an agent that can execute and an agent that knows what it is permitted to execute is the defining AI infrastructure problem of 2026. And the fact that Google, Palantir, Microsoft, and Gartner are all converging on it in the same quarter is not a coincidence. It is a signal.
The timing is not accidental. Deloitte’s 2026 State of AI report tells the story in two numbers: only 20% of organizations are growing revenue through AI today, while 74% are counting on it. In the next six months, the number with AI in production will double. That is the pressure event, a collision between ambition and architecture, arriving right now. Whether enterprises are ready or not.
When AI moves from pilot to production, the questions change completely. It is no longer “does this work in a test environment?” It is “can I trust this to act on behalf of my enterprise, in front of a customer, under a regulatory obligation, at 2am?”
As industry analysts noted, once applications hit real users and real revenue, latency, concurrency, and cost per query become non-negotiable. Organizations will have to design AI-native infrastructure from ground up. (Solutions Review, 2026)
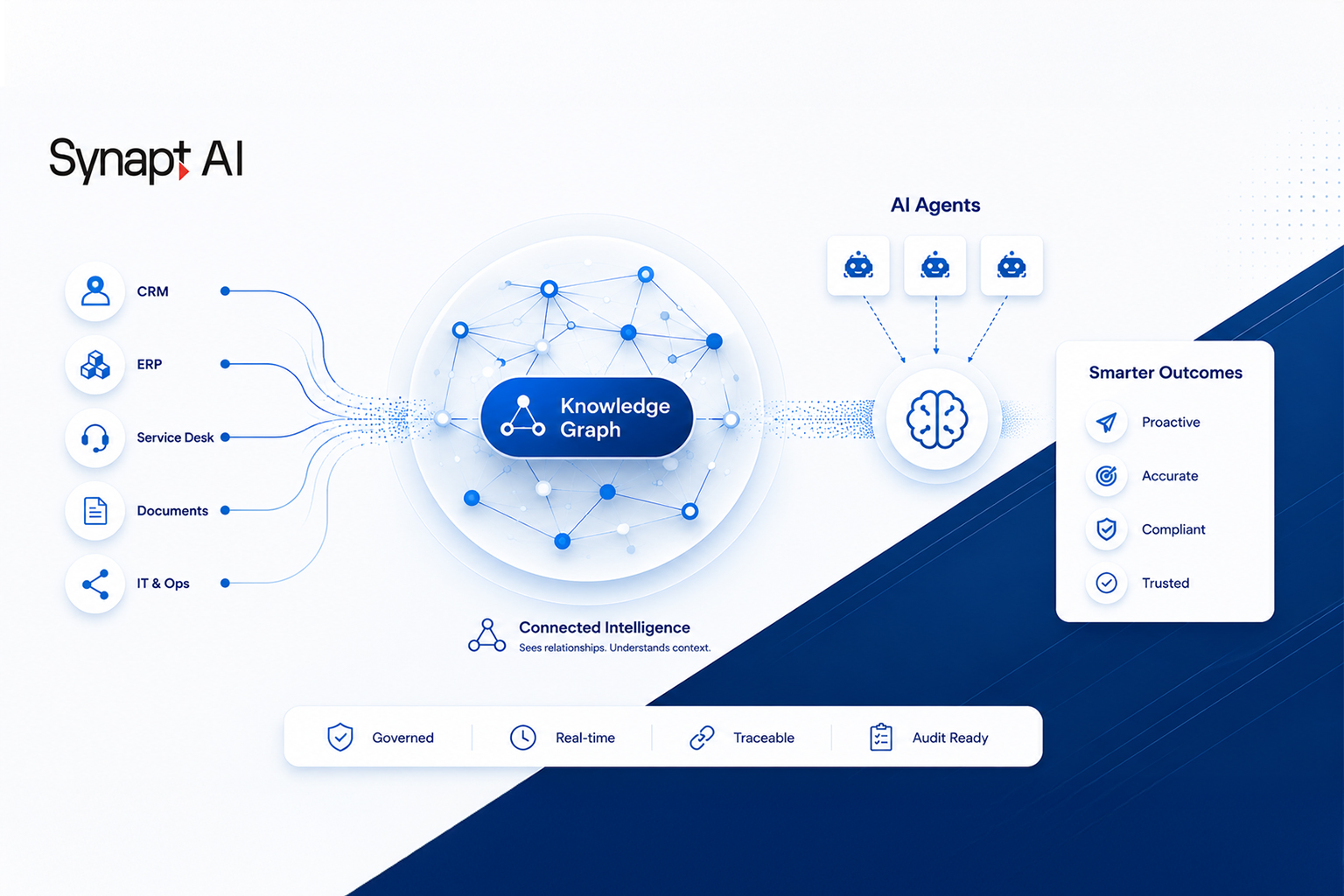
That infrastructure has a name. The market is still arguing about what to call it. But everyone building serious enterprise AI in 2026 is building the same thing — a context layer that encodes how the enterprise works, what its agents are permitted to do, and why every decision they make is defensible.
Gartner predicts that more than 50% of AI agent systems will leverage context graphs by 2028. The reason is unambiguous: context graphs capture the decision logic, workflows, and institutional memory that AI agents need to act reliably in production.
That is the right framing. These are not data problems. They are procedural AI problems, and they demand a different kind of architecture than the retrieval systems most enterprises have already invested in.
The major platforms — Google’s Knowledge Catalog, Palantir’s Ontology, and Microsoft’s governed workflows — are all heading in the right direction. But most enterprise implementations stop at the data layer. Enterprises successfully scaling autonomous AI are going a level deeper, to the procedural layer: encoding not just what the organization knows, but how it operates and what its AI agents are explicitly permitted to do.
“Autonomy without grounding is dangerous. The difference between a useful agent and a hallucinating one will depend on the quality of its foundation.”
Here is where the conversation gets urgent and where most enterprise leaders are not spending enough time.
This is not traditional technical debt that can be paid down over time. It is opportunity cost compounding in real-time. Forrester predicts that by 2026, 75% of technology decision-makers will face moderate to severe levels of this new AI-driven debt. For those already carrying it, the cost is visible: up to 40% more spent on maintenance, and features shipping 50% slower than their more agile competitors.
The compounding mechanism is this: every AI agent deployed without a procedural grounding layer is an agent making decisions on inference rather than policy. Every decision made on inference rather than policy is a decision that cannot be fully explained, audited, or defended. Every unexplainable decision is a liability — regulatory, reputational, or operational. And every quarter spent accumulating these liabilities makes the eventual reckoning more expensive.
By the end of 2026, the distinction between AI-native organizations and AI-adopter organizations will likely become permanent. Those who haven’t deeply embedded AI by then will face talent that won’t stay, investment that will dry up, and customers who will notice.
For the hyperscalers, the race to own the context layer is existential. Whoever becomes the default substrate for enterprise AI reasoning owns the stickiest infrastructure in the stack. This is why Google Cloud Next ’26 was not about models. It was about governance infrastructure. The model is now a commodity. The layer above it is the product.
For specialist vendors, the question is whether their procedural grounding is deep enough to survive contact with regulated enterprises. Many have the right idea conceptually, but the delivery models that worked in government and defense do not translate to the broader enterprise market. Most businesses do not have the budget or timeline for long contracts and embedded engineering teams. The vendors that win will be the ones who can deliver that same depth at commercial speed.
For enterprise leaders — CIOs, COOs, Chief AI Officers — the question is simpler and more urgent: are you building the substrate, or are you waiting?
McKinsey’s research makes the divide clear. The companies pulling ahead are not the ones deploying the most AI. They are the ones building clean, governed foundations that new capabilities can actually scale on. Every organization that skips that step and bolts AI onto an ungoverned stack is not transforming. It is accelerating the very AI technical debt it was trying to escape.
Everyone is talking about context because context is the last unsolved problem before autonomous AI becomes trustworthy enough to run enterprise operations.
The conversation has moved from “which model?” to “how do we govern?” to — finally, this quarter — “how does AI know what it is permitted to do?”
That last question is the one that matters. Answering it with policy documents, dashboards, and audit logs produces something that looks like AI governance but acts like a bottleneck. The enterprises that answer it architecturally will have autonomous operations in 2026.
CTA: Your data stays where it is. Your systems stay as they are. What changes is the layer that makes them intelligent enough to act. Connect with us today to build it.