5.1 Understanding the Knowledge Graph
After data is ingested into a Context Provider, the platform automatically creates a knowledge graph. The ingestion process extracts entities from your documents and maps the relationships between them. A grounding step verifies each entity and relationship against the source material before it enters the graph, ensuring that the structured context agents reason over is constrained to what was actually confirmed in your data.
The graph is built through a five-stage pipeline that runs automatically in the background from the moment a document is submitted. The document is first normalised and parsed to preserve its structure — section hierarchy, tables, and reading order are all retained so that downstream extraction has proper context. The parsed content is then split into semantic chunks, each of which is enriched with LLM-generated metadata and converted into a vector embedding for semantic search.
In the fourth stage, the Knowledge Service processes each chunk and extracts four types of structured knowledge. Entities are named things in your content — people, systems, policies, processes, and more — classified across over eighty entity types. Relationships are the connections between those entities, grounded back to the source chunks to prevent hallucinated links. Concepts are the broader ideas and themes the platform identifies within the content. Propositions are atomic, verifiable statements in subject–predicate–object form — for example, Ticket Resolution Policy governs the AT&T support workflow — giving the agent a natural-language layer of factual statements to reason from. Across all chunks, extracted entities are deduplicated and canonicalized so the same real-world thing is never represented twice in the graph under different names.
The extraction behaviour is shaped by the Extraction Mode you select when creating the Context Provider. Fast is the default and suits most use cases. Balanced applies more careful extraction with fewer false positives. Precise is the most conservative mode, minimising noise at the cost of some recall. Comprehensive maximises extraction coverage and is suited to content-dense domains where recall matters more than precision.
In the final stage, all extracted entities, relationships, concepts, and propositions are persisted to the knowledge graph in Neo4j, while vector embeddings are stored in Milvus. This hybrid graph-vector store is what enables agents to perform both semantic similarity search and structured graph traversal when answering queries from within the provider.
5.2 Navigating the Graph Visualisation
Opening the Graph View
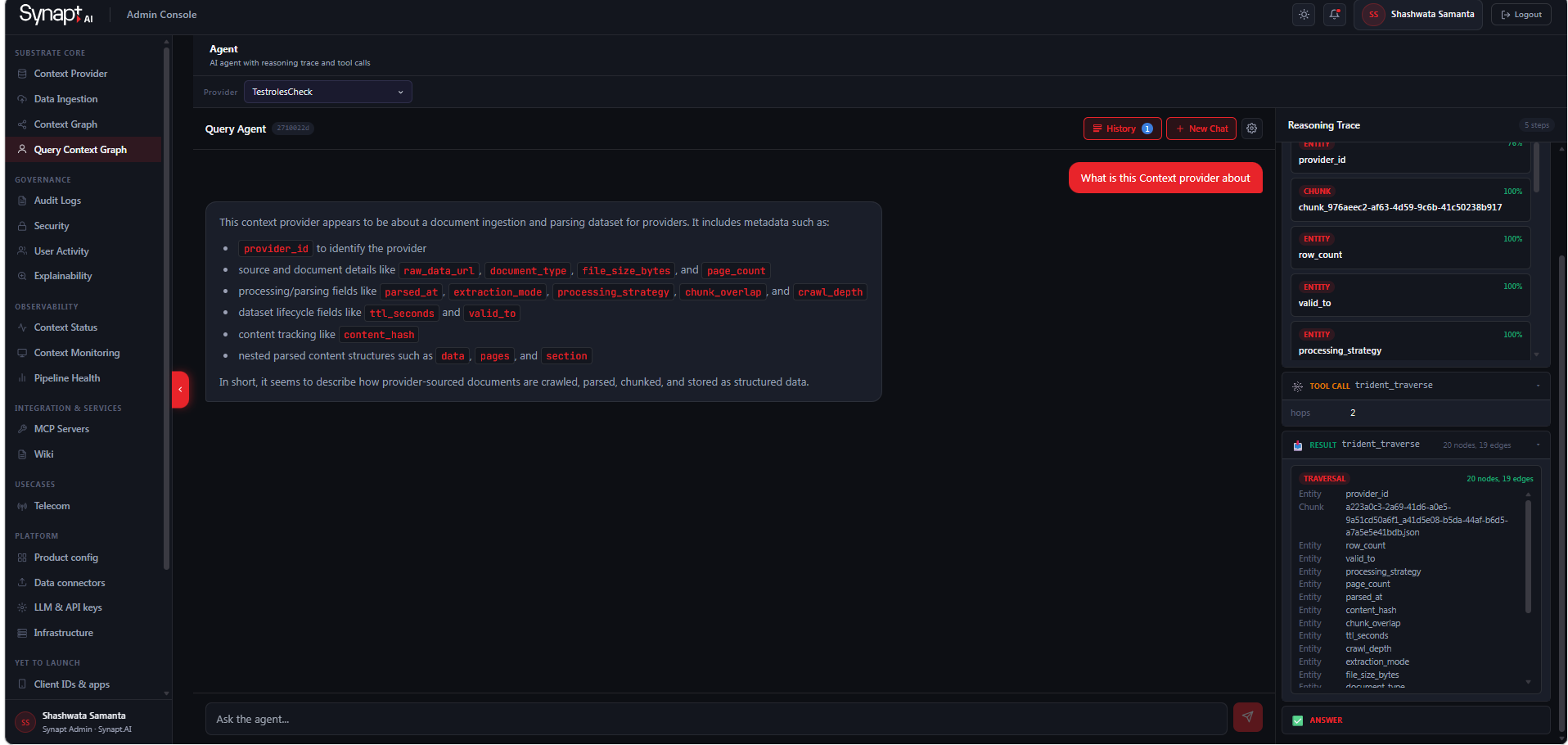
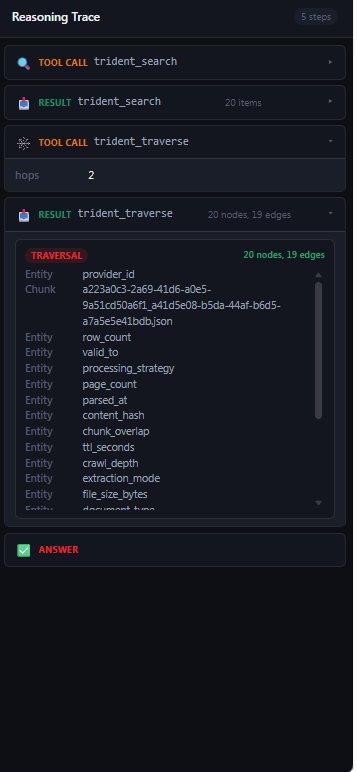
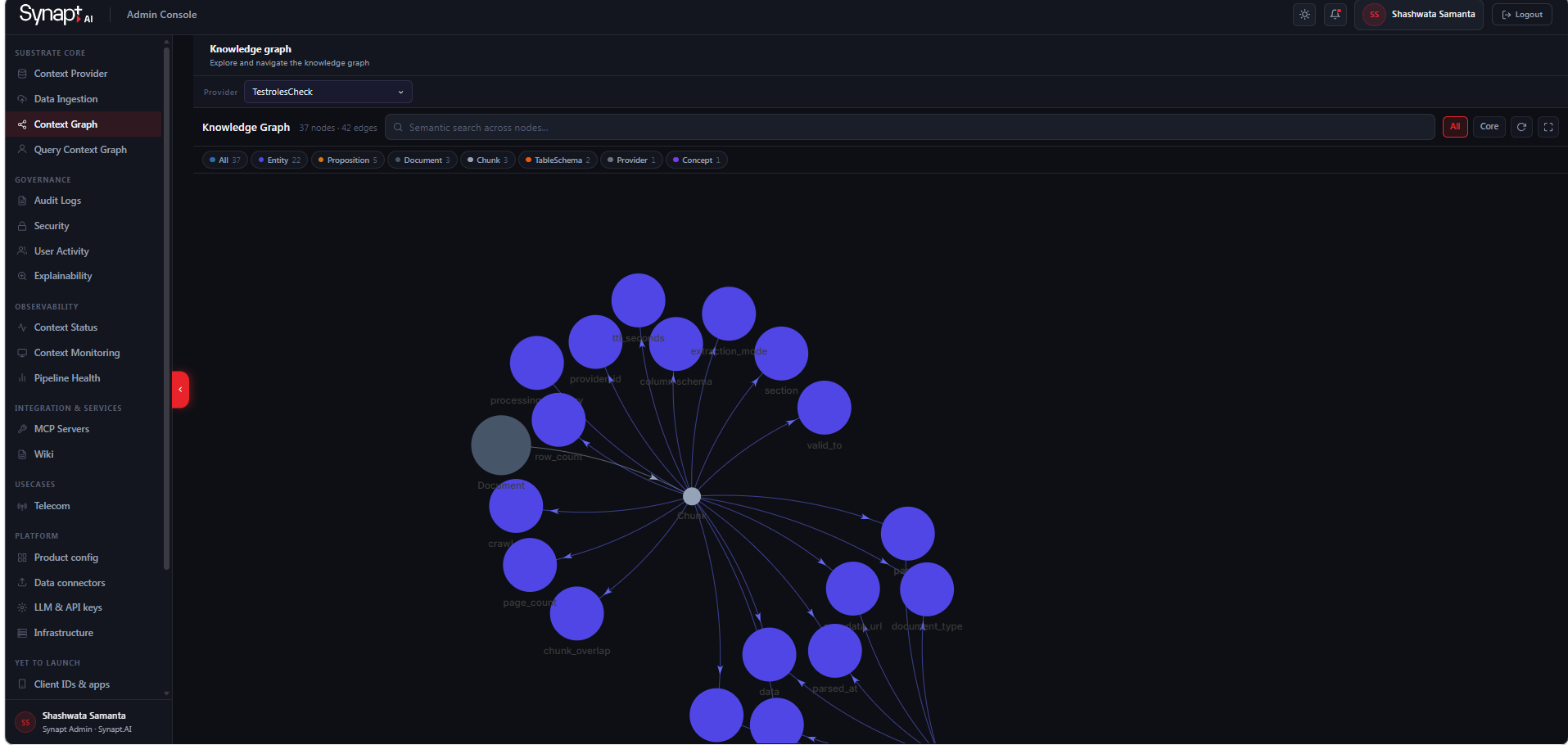
From the left sidebar, navigate to Substrate Core → Knowledge Graph. At the top of the page, use the Provider dropdown to select the Context Provider whose knowledge graph you want to explore. The graph canvas loads automatically and displays a summary of the total nodes and edges present in the selected provider — for example, 40 nodes · 0 edges.
Zooming and Panning
Use your mouse scroll wheel to zoom in and out on the graph canvas. Click and drag anywhere on the canvas to pan across the graph. Nodes reposition themselves dynamically as you navigate. To reset the view to fit all nodes on screen, use the expand icon in the top right corner of the canvas.
Filtering by Node Type
A row of filter tabs sits above the graph canvas. Click All to view every node in the graph together. Click Entity, Concept, Procedure, or Stop to isolate nodes of that type. For more granular filtering, use the coloured filter pills to the right — these let you toggle specific subtypes such as Propositions, Entities, Concepts, Chunks, Providers, and Documents on or off individually. The count shown on each pill indicates how many nodes of that type exist in the current provider.
Searching Nodes
The search bar at the top of the canvas reads Semantic search across nodes. Type any term to perform a semantic search across all nodes in the selected provider. Matching nodes are surfaced from across the graph regardless of their current position on screen.
Selecting a Node
Click any node on the canvas to select it. The right-hand panel opens automatically and displays the full detail for that node, including its type badge (Entity, Concept, Procedure, etc.), its name and description, and three summary counts — Connections, Edge Types, and Node Types. Below the summary, the Properties section shows the node’s extracted attributes — for an Entity node this includes entity type, confidence score, label, aliases, and a unique entity ID. The Connections section at the bottom lists what the node is linked to, including any source Chunks it was mentioned in.
5.3 Entity Types and Relationships
Structural links are automatically created when a document is processed — they capture basic containment like “this document has these sections” and “this section mentions these things.” These are straightforward, predictable connections. Semantic links are the more meaningful, content-driven connections extracted from the actual text. They fall into 8 categories: Organization — who works for whom, reporting structures, team memberships. Business — commercial relationships like partnerships, vendor-customer links, contracts. Process & Workflow — what triggers what, what depends on what, what governs a process. Technology — how systems connect, what runs where, what integrates with what. Data — how data flows between systems — what reads from or writes to what. Security & Governance — who or what controls access, authorization chains. Software — code-level connections like one function calling another, or a module depending on a library. Time & Version — when things were created, how versions relate to each other, lifecycle stages.
Entity Types
The platform recognises 80+ entity types organised across 7 categories. Every node in the graph is assigned exactly one entity type at ingestion time, and that type is visible in the node detail panel as the entity_type property.
Relationship Types (50+ across 8 categories)
How Entities and Relationships Display
In the graph visualisation, each entity appears as a coloured node on the canvas — the colour corresponds to its category, making it easy to scan the graph by domain at a glance. Clicking any node opens the detail panel on the right, which shows:
-
Entity Badge — Displays the node classification (e.g., ENTITY, CONCEPT).
-
Name and Description — The canonical name and a short, extracted description.
-
Confidence Score — The extraction model’s confidence (e.g., 0.92).
-
Entity Type — The assigned type from the taxonomy (e.g., TECHNOLOGY).
-
Connections — Count of incoming and outgoing edges, with a breakdown by edge type and connected node types.
-
Mentions — Links to the source document chunks from which this entity was extracted, providing full traceability back to the original text.
5.4 Confidence Scores on Knowledge
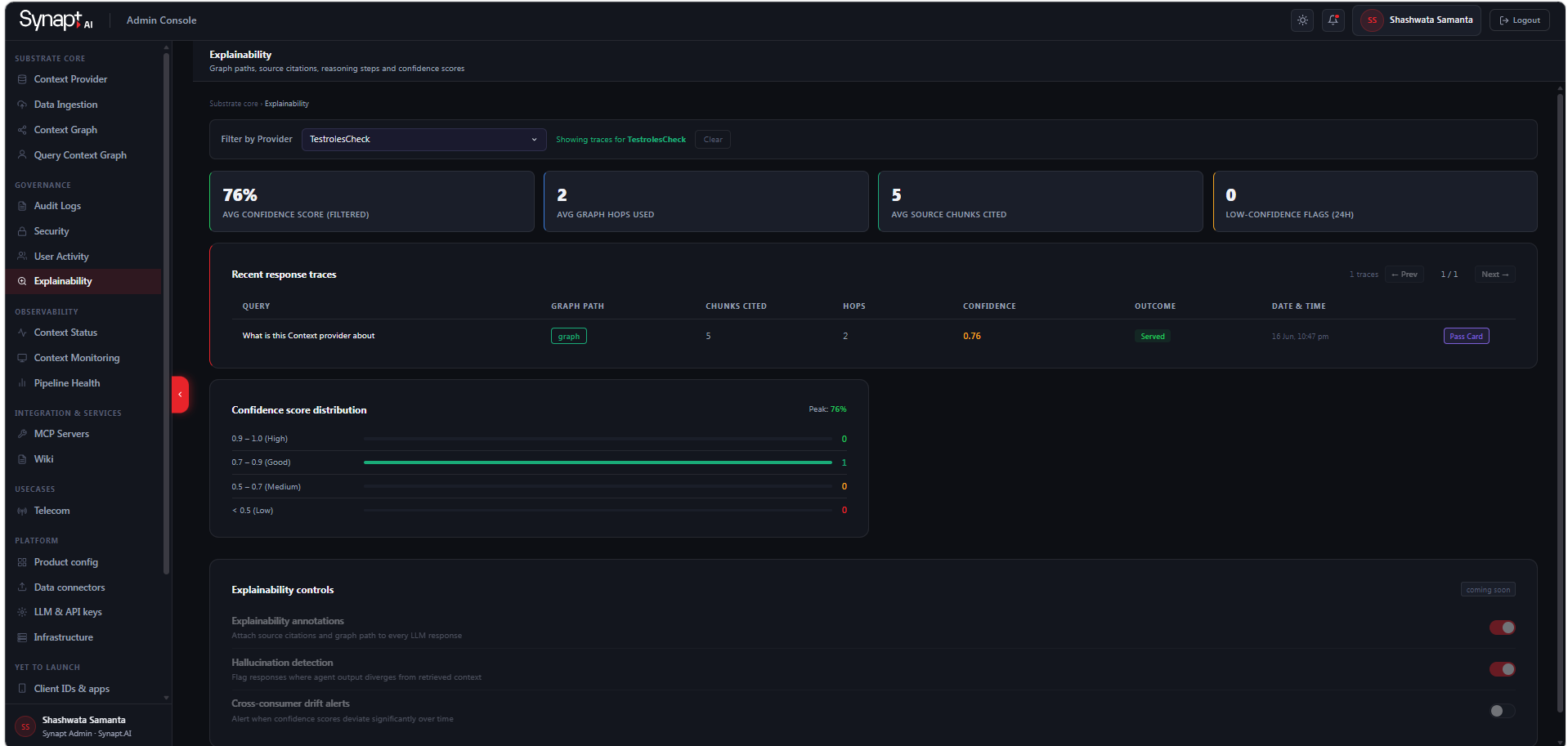
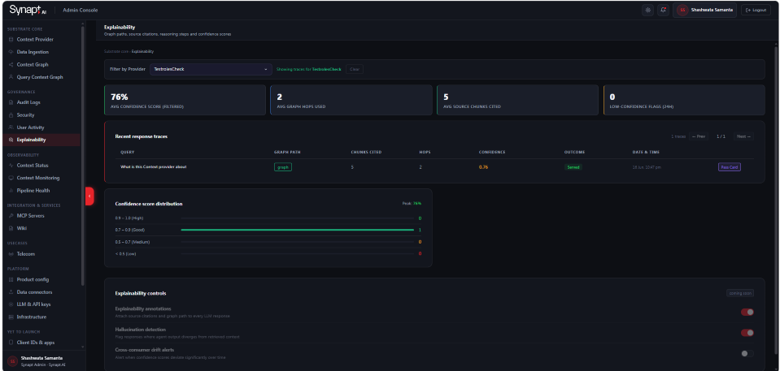
Every fact in the knowledge graph carries a confidence score. This score is based on retrieval strength, graph-match quality, and the number of independent sources that corroborate the fact. Confidence scores are visible on graph nodes and are used by agents to determine whether to act on the knowledge or defer to a human when confidence is below a configurable threshold.
Score Range
Confidence scores run from 0.0 to 1.0. All extracted objects — entities, relationships, concepts, and propositions — receive an individual score at ingestion time. The score reflects the extraction model’s certainty about the object and is stored as a property on every node and edge in the graph.
-
0.90 – 1.0 — High confidence. The fact is well-supported by the source text and can be acted
on directly.
-
0.75 – 0.89 — Moderate confidence. Reliable for most use cases.
-
0.65 – 0.74 — Low-moderate confidence. Review is recommended before acting on the fact.
-
Below 0.65 — Low confidence. The fact is flagged for human review before being committed
to the graph.
How Confidence Scores Display in the UI
In the graph visualisation, the confidence score for any entity or relationship appears in the node detail panel on the right side of the screen when you click a node. It is shown numerically alongside the entity name, type, and description (for example, confidence: 0.92). Nodes with lower confidence scores may also carry a visual indicator distinguishing them from high-confidence entries, making it easier to identify areas of the graph that warrant closer review.
When reviewing search results or agent-generated responses, the confidence of the underlying knowledge influences how the agent presents the answer — high-confidence facts are stated directly, while lower-confidence facts may be qualified or surfaced with a note that human validation is recommended.
Configurable Thresholds
Two thresholds govern how confidence scores affect downstream behaviour, and both are configurable by a platform administrator:
-
The extraction review threshold (default 0.65) controls which facts are flagged before being written to the graph. Any entity, relationship, concept, or proposition extracted with a confidence score below this value is routed to a review queue in the Tristore rather than written directly. A reviewer can validate or discard the fact before it becomes part of the live knowledge graph.
-
The entity resolution threshold (default 0.75) governs when two similar entities are merged into a single canonical node. If the similarity score between a new entity and an existing one exceeds 0.75, they are treated as the same real-world object and merged. Entries that score near this boundary — where a merge could reasonably go either way — are logged for audit, and administrators can inspect and correct merge decisions if needed.
Both thresholds balance precision (avoiding incorrect merges or low-quality facts entering the graph) against recall (ensuring that useful but uncertain knowledge is not silently discarded). They can be tuned per deployment based on the quality of your document corpus and the risk tolerance of your use case.
5.5 Freshness and Data Lineage
Every piece of knowledge in the graph is stamped with a full provenance trail at the time it is ingested. This tells you not only what the platform knows, but when it learned it, where it came from, and how long it remains valid.
Viewing Freshness Timestamps
When a document is ingested, the platform records a parsed_at timestamp in ISO 8601 format (e.g., 2025-05-18T10:00:05+05:30). This timestamp travels with every chunk and extracted object derived from that document and is visible in the node detail panel when you click any entity in the graph view.
Knowledge freshness is also governed by a Time-to-Live (TTL) value set at ingestion. When content is submitted, a ttl_seconds value is assigned — for example, 86400 seconds for a 24-hour window. The platform computes an expiry point (valid_from + ttl_seconds) and schedules automatic deletion of the corresponding graph nodes when that time is reached. This ensures that time-sensitive content — such as incident reports, sprint plans, or policy drafts — does not persist in the graph beyond its intended validity period. Once expired, the nodes are removed and the knowledge is no longer surfaced in queries or agent responses.
What Data Lineage Looks Like
Data lineage in Synapt.AI is a chain that runs from every graph node all the way back to the exact sentence in the original source file. Each entity, relationship, concept, and proposition carries three key provenance fields:
-
source_chunks — IDs of the specific text chunks from which the object was extracted
-
extraction_job_id — unique identifier of the pipeline run that produced the object
-
document_id — UUID of the source document at ingestion
Knowledge freshness is governed by a Time-to-Live (TTL) value set at ingestion. Once expired, nodes are removed and the knowledge is no longer surfaced in queries.
To trace a fact to its origin, click the entity node in the graph. The detail panel shows a Mentions section listing the source chunks linked to that entity. Clicking a mention opens the corresponding chunk, showing the exact passage of text and the source document name.
5.6 Editing and Managing Graph Content
The knowledge graph in Synapt.AI is built and maintained entirely through the ingestion pipeline. Individual nodes and relationships cannot be manually added or edited through the graph visualisation UI — all graph content originates from documents submitted through a Context Provider. This design ensures that every fact in the graph has a verifiable source, a confidence score, and a full provenance trail.
Updating Knowledge
If a source document changes — for example, a policy is revised or an SOP is updated — the correct way to update the graph is to re-ingest the updated file through the same Context Provider. The pipeline uses a merge-and-update approach: nodes derived from the same document are updated in place, and new entities or relationships introduced in the revised version are added. This keeps the graph consistent with the latest version of your source content.
Removing Content
Content can be removed at the Context Provider level. Deleting a Context Provider triggers a cascading removal of all knowledge derived from it — every entity, relationship, concept, proposition, and chunk associated with that provider is purged from the graph and the vector store.
-
A cp_admin can soft-delete (archive) a Context Provider. Archived providers are disabled and their knowledge is no longer surfaced in queries, but the data is retained and can be restored if needed.
-
A synapt_admin can hard-delete a Context Provider permanently. This is irreversible and removes all associated graph nodes, vectors, and metadata.
There is no way to delete an individual node or relationship in isolation without removing the provider or re-ingesting the source document.
Low-Confidence Review
Entities, relationships, concepts, and propositions extracted with a confidence score below the configured threshold are held in a review queue before being written to the graph. A reviewer can validate or discard these items, giving human oversight over uncertain extractions without blocking the rest of the pipeline.
Audit Trail
Every write, deletion, and provider lifecycle event is recorded in the platform’s audit log with the caller’s identity, timestamp, and action taken. This provides a complete chain of custody for all graph content — including what was removed, who removed it, and when.