Ask any enterprise AI team what their stack looks like, and you will hear a version of the same answer.
Cloud infrastructure. A foundation model — GPT-4, Claude, Gemini, or an open-source alternative. A data platform. Maybe a vector database. A few agents built on top.
It sounds complete. It isn’t.
There are three layers every enterprise AI stack needs to move from pilot to production. Most enterprises have two. The third — the one that actually determines whether AI agents work in the real world is almost universally absent.
Layer one: Compute
The cloud providers solved this. AWS, Azure, and Google Cloud have made enterprise-grade compute accessible, scalable, and increasingly cost-efficient. GPU capacity that once required years of capital planning is now provisioned in minutes.
This layer is not the problem. If anything, compute abundance has created a false sense of readiness — enterprises assume that because the infrastructure is in place, the AI is ready to work.
It isn’t. Compute is necessary but nowhere near sufficient.
Layer two: Data
The second layer is the data platform — the warehouses, lakes, pipelines, and databases that enterprises have spent the last decade building. Snowflake, Databricks, BigQuery. Years of investment in ETL, schema design, and data governance.
This layer is also largely in place. Enterprises have more data than they have ever had. The average large enterprise holds petabytes of operational data across CRM systems, ERP platforms, ticketing tools, policy repositories, and communication records.
And yet 83% of enterprises are building agentic AI while only 11% are shipping it. The data is there. The agents are not working.
Because data is not the same as context.

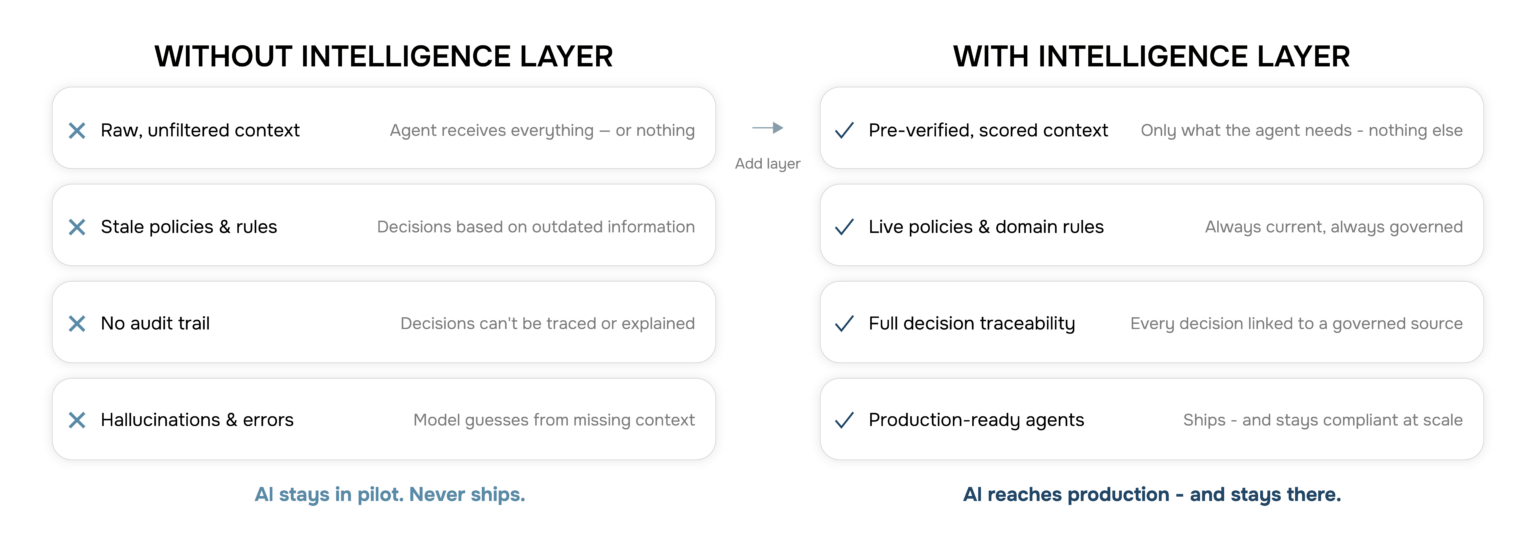
Layer three: Operational intelligence — the missing layer
Here is where every enterprise AI stack quietly breaks down.
An AI agent deployed in a regulated industry does not just need data. It needs to know which data is up to date. It needs to determine which policies apply to this customer in this region under this scenario. It needs access to the workflows that govern decision-making — not as static documents buried in a SharePoint folder, but as live, queryable, governed knowledge that updates as the business changes.
This is operational intelligence. And it is not a database. It is not a RAG pipeline. It is not a prompt with a few policy documents pasted in.
Operational intelligence is the layer that sits between an enterprise’s fragmented data systems and the AI agents that need to act on them. It encodes the policies, procedures, compliance constraints, and domain knowledge that define how the business actually runs — and makes that knowledge accessible, current, and governed for every agent that needs it.
Without this layer, agents hallucinate — not because the model is wrong, but because the model was never given what it needed to be right. They give customers outdated policy information. They approve requests that should have been blocked. They make decisions that cannot be explained to a regulator.
The enterprise has the data. The agent just cannot see it.
Why is this layer hard to build
The reason operational intelligence does not exist in most enterprise stacks is not neglect. It is genuine complexity.
Enterprise knowledge is not tidy. Policies conflict across regions. Procedures change faster than documentation. Compliance rules interact in ways that require domain expertise to navigate. The knowledge that experienced humans carry — the institutional understanding of how things actually work — has never been formally encoded anywhere.
Building this layer means solving problems that are simultaneously technical, organisational, and domain-specific. It requires a governance model, a retrieval architecture, a confidence scoring mechanism, and a continuous update pipeline. It requires understanding the business deeply enough to know what the agents need to know.
This is why most enterprises skip it. They build the agent first and assume the context problem will solve itself. It does not.
The infrastructure question enterprises should be asking
The enterprise AI conversation has been dominated by model selection for three years. Which foundation model? Which version? Which benchmark?
The right question is different: what sits between your data and your agents?
Compute is solved. Data is abundant. The enterprises that win the next five years will not have the best models. They will have the best operational intelligence layer beneath them.
That is the layer most enterprises are missing. And it is the only one that determines whether AI moves from demo to production.

