A 350-million parameter model just tripled ChatGPT’s score on agentic tool calling. A 500-million parameter model hit 94% accuracy on a security classification task that stumped zero-shot LLMs. A fine-tuned Mistral variant is running in production at Microsoft, beating larger models on both quality and latency.
The era of “bigger is better” in enterprise AI is ending. Not because large language models are getting worse — they aren’t — but because a new class of small, purpose-built models is proving that for the tasks enterprises care about, targeted training beats raw scale. And the gap isn’t closed.

The evidence is hard to argue with
The most striking result comes from a study on agentic tool calling — the ability of an AI model to select and invoke the right APIs and functions to complete a task. Researchers fine-tuned Facebook’s OPT-350M, a model with roughly 500 times fewer parameters than GPT-4-class models, using reinforcement learning on the ToolBench benchmark. The result: 77.55% pass rate, compared to ChatGPT with chain-of-thought prompting at 26%, ToolLLaMA-DFS at 30.18%, and ToolLLaMA-CoT at 16.27%.
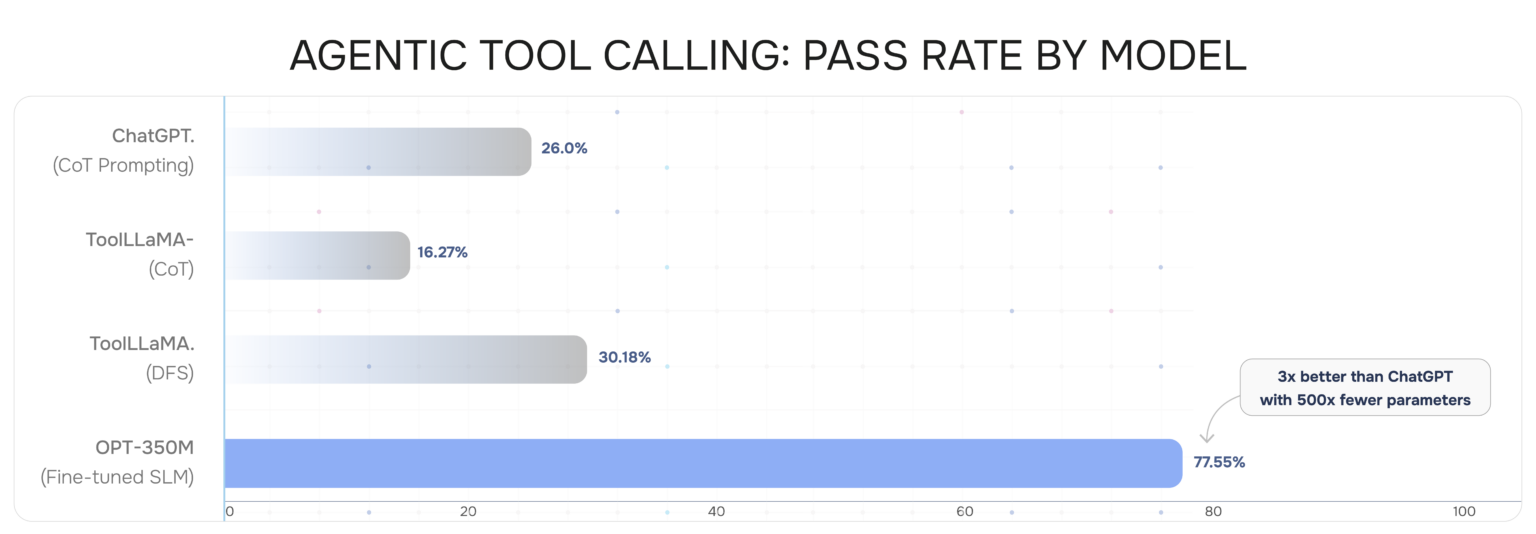
Figure 1 — Agentic tool calling pass rate: fine-tuned OPT-350M vs. larger models
| Read that again. A model that fits on a smartphone beat the largest commercial LLM by a factor of three on a practical agentic task. |
This isn’t an isolated finding. In April 2026, Microsoft published results from their production deployment of small Mistral variants fine-tuned for domain-specific code generation. The SLMs outperformed larger models on both output quality and inference latency — and they’re running in production, not just on benchmarks. The paper also demonstrated per-customer customization: each enterprise customer can have a fine-tuned variant tailored to their specific domain language, something that is economically infeasible with 100B+ parameter models.
Meanwhile, a team studying SMS threat detection built an autonomous distillation pipeline that trained a Qwen2.5-0.5B model to 94.31% accuracy — comparable to human-level classification — without a single labeled training example. The teacher LLM generated all the training data synthetically, the student SLM learned from it via LoRA fine-tuning, and the whole loop ran on consumer hardware.
The pattern across all of these is the same: when the task is well-defined and the training is targeted, small models don’t just match large ones — they win.
Why targeted training beats raw scale
The intuition behind these results is simple. Large language models are generalists. They allocate parameters across every domain, every language, every task type. When you ask GPT-4 to make an agentic tool call, it’s drawing on the same parameters it uses for poetry, medical diagnosis, and Minecraft tutorials. Most of that capacity is irrelevant to the task at hand.
An SLM fine-tuned on a specific task class concentrates all of its capacity on that one thing. A 350M model trained exclusively on tool-calling patterns doesn’t need to know how to write sonnets. It doesn’t need multilingual capability. It doesn’t need to reason about physics. Every parameter is allocated to the exact skill it needs.
This is especially true for enterprise applications, where the task space is well-defined. A telecom network troubleshooting agent doesn’t need to know about Renaissance art. An insurance claims processor doesn’t need to generate Python code. Enterprise AI is, by nature, domain-specific — and domain-specific is exactly where SLMs excel.
The distillation revolution
If SLMs are the answer, the next question is: how do you build them efficiently? The research points to knowledge distillation as the primary method, and two distinct approaches are maturing rapidly.
Approach 1: Chain-of-thought guided reinforcement learning
A March 2026 study compressed Qwen 3B down to Qwen 0.5B — a 6x size reduction — while retaining 70–91% of the teacher’s capability in English, up to 95% in Spanish, and 93.5% Rouge-L on code generation. The key innovation: instead of just training the student on the teacher’s outputs, the researchers used the teacher’s chain-of-thought reasoning as a supervision signal during RL training. This taught the student not just what to output, but how to reason.
Multilingual retention is particularly notable for global enterprises. A 500M model that retains 95% of a 3B model’s Spanish capability opens the door to multilingual SLMs that serve diverse markets without the infrastructure cost of large models.
Approach 2: Autonomous agentic distillation
The SMS threat detection study introduced a fully autonomous training pipeline. A teacher LLM generates synthetic training data; the student SLM trains on it; performance is evaluated; the teacher adjusts the data based on the student’s weaknesses; and the loop repeats until performance plateaus. No human intervention. No labeled datasets.
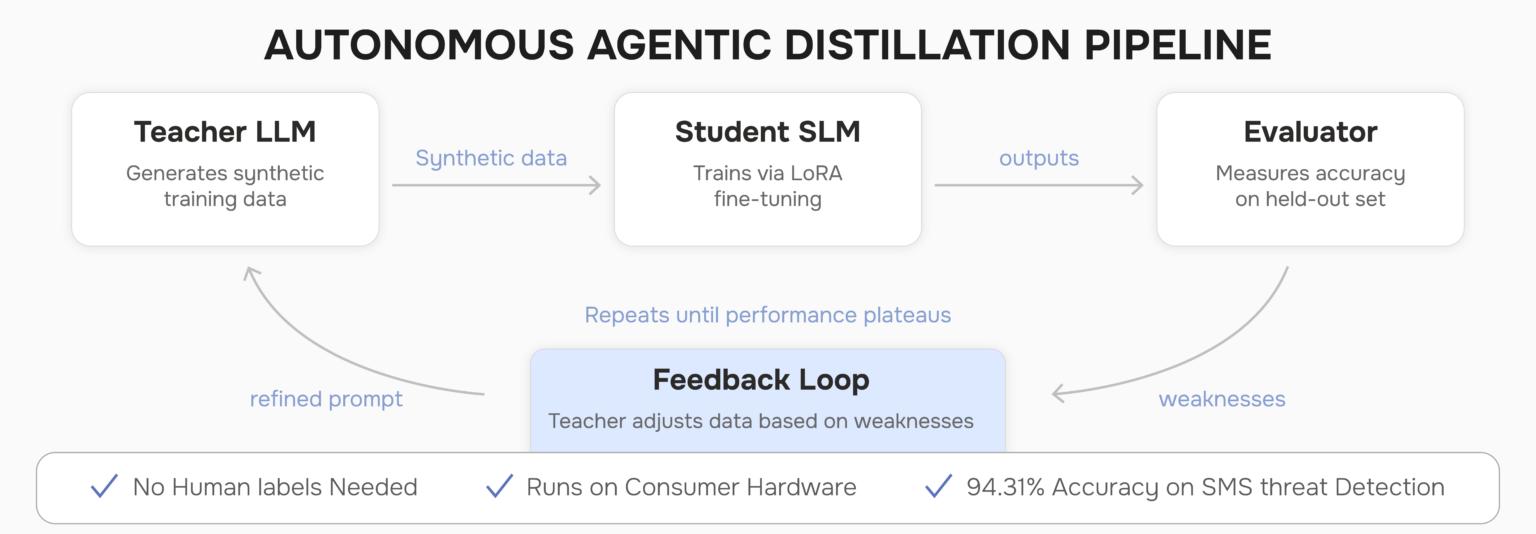
Figure 2 — Autonomous agentic distillation loop: no human labels required
This matters enormously for enterprise domains where labeled data is scarce or expensive. Getting expert-annotated training data for telecom network troubleshooting or insurance claims processing costs real money and real time. An autonomous distillation loop that generates its own training data removes that bottleneck entirely.
| Critical finding: the choice of teacher LLM swings student performance by over 25 percent. Claude and DeepSeek substantially outperformed GPT and Gemini as teachers. Enterprises building SLM training pipelines need to benchmark teacher models carefully. |
The compression recipe: order matters
Building a good SLM is one thing. Making it small enough to deploy efficiently is another. UniComp, the first unified evaluation of LLM compression techniques, tested every combination of pruning, knowledge distillation, and quantization across 40 datasets. Their finding is concrete and actionable:
| Optimal ordering: Prune first, then Distill, then Quantize (P → KD → Q), achieving 3.68× compression while preserving strong capabilities. |

Figure 3 — The P → KD → Q compression pipeline and why ordering is critical
The ordering isn’t a suggestion — it’s critical. The study found that applying quantization early in the pipeline causes “severe, irreversible information loss that impairs subsequent training.” Quantization is a lossy operation, and information destroyed early cannot be recovered by later distillation. But when quantization comes last — after pruning has removed redundant structure and distillation has transferred knowledge efficiently — the remaining model is robust enough to withstand precision reduction.
This gives enterprise teams a concrete recipe:
- Prune the base model to remove structural redundancy
- Distill from a larger teacher using CoT-guided RL or autonomous synthetic data
- Quantize to 4-bit for deployment
The result: models that are 3–4x smaller than the distilled version alone, with acceptable quality loss, deployable on standard enterprise hardware.
UniComp also surfaced a sobering finding: performance on benchmarks doesn’t guarantee reliability. A model can score well on accuracy metrics while behaving inconsistently in production. This is a reminder that compression pipelines need to be evaluated on reliability metrics, not just benchmark scores — especially for enterprise use cases where consistency matters more than peak performance.
What this means for enterprise AI
The implications of these findings converge on a single conclusion: the future of enterprise AI is not one giant model serving every use case. It’s a fleet of small, purpose-built models, each trained for a specific domain and task class.
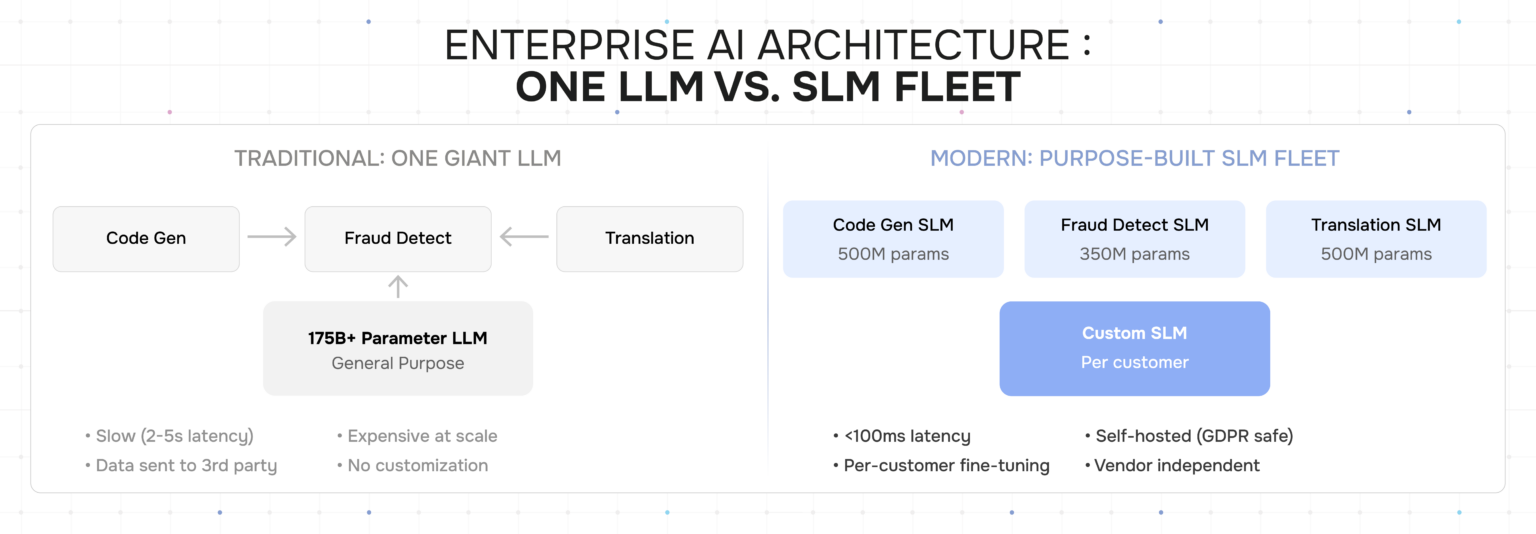
Figure 4 — Traditional single-LLM architecture vs. purpose-built SLM fleet
Consider the economics. A 350M parameter model serving agentic tool calls requires roughly 500x less compute per inference than a 175B+ parameter model. In a self-hosted deployment where the enterprise is paying for GPU hours, that’s the difference between needing a cluster of A100s and running on a single mid-tier GPU. At enterprise scale — millions of agent invocations per day — the cost difference is measured in millions of dollars annually.
But cost is just the beginning. The real advantages are:
- Latency. Enterprise applications have real-time requirements. A customer-facing agent can’t wait 3 seconds for an LLM API response. Small models running locally deliver sub-100ms inference — fast enough for real-time decision-making in production workflows.
- Data sovereignty. Large model APIs send enterprise data to third-party servers. SLMs run on-premise. For industries under GDPR, DORA, Solvency II, or the EU AI Act, this isn’t a preference — it’s a legal requirement. Self-hosted SLMs eliminate the data residency problem entirely.
- Customization at scale. Microsoft’s production results show that per-customer SLM variants are feasible. Each enterprise customer gets a model fine-tuned on their specific domain language. Try doing that with a 175B parameter model — the fine-tuning cost alone would be prohibitive.
- Vendor independence. A fleet of self-hosted SLMs means zero dependency on OpenAI, Anthropic, Google, or any other foundation model provider. When pricing changes, rate limits tighten, or a provider goes through a rough patch, your production systems keep running.
The road ahead
SLMs aren’t a replacement for large language models in every context. General-purpose chat, open-ended reasoning, creative writing — these still benefit from the breadth that comes with scale. But for the specific, well-defined tasks that make up most enterprise AI workloads, the research is unambiguous: small, targeted, and fine-tuned beats large, general, and expensive.
The pieces are falling into place. We have evidence that SLMs outperform LLMs on targeted tasks. We have multiple distillation approaches that make SLM training practical and affordable. We have a concrete compression recipe (P → KD → Q) that makes deployment efficient. And we have production validation from teams running these models in real enterprise environments.
| The enterprise AI stack of the near future doesn’t call an API. It runs a fleet of domain-specific SLMs — self-hosted, governed, and purpose-built. The models are small. The impact is not. |